Analisi e previsione di serie temporali. Metodi di previsione delle serie temporali. Metodi di previsione esperti
Le tre note precedenti descrivono modelli di regressione che prevedono la risposta dai valori delle variabili esplicative. In questo post, ti mostriamo come utilizzare questi modelli e altre tecniche statistiche per analizzare i dati raccolti in intervalli di tempo successivi. Sulla base delle specificità di ciascuna società menzionata nello scenario, prenderemo in considerazione tre approcci alternativi all'analisi delle serie temporali.
Il materiale sarà illustrato con un esempio trasversale: prevedere il reddito di tre società... Immagina di essere un analista in una grande società finanziaria. Per valutare le prospettive di investimento dei tuoi clienti, devi prevedere i guadagni di tre società. Per fare ciò, hai raccolto dati su tre società di tuo interesse: Eastman Kodak, Cabot Corporation e Wal-Mart. Poiché le aziende differiscono nel tipo di attività commerciale, ogni serie storica ha le sue caratteristiche uniche. Pertanto, è necessario utilizzare modelli diversi per la previsione. Come scegliere il miglior modello di previsione per ogni azienda? Come valutare le prospettive di investimento in base ai risultati delle previsioni?
La discussione inizia con un'analisi dei dati annuali. Vengono dimostrati due metodi per livellare tali dati: media mobile e livellamento esponenziale. Viene quindi illustrata la procedura per il calcolo del trend utilizzando il metodo dei minimi quadrati e metodi di previsione più sofisticati. Infine, questi modelli sono estesi alle serie storiche basate su dati mensili o trimestrali.
Scarica la nota nel formato o, esempi nel formato
Previsione negli affari
Poiché le condizioni economiche cambiano nel tempo, i manager devono anticipare l'impatto che questi cambiamenti avranno sulla loro azienda. La previsione è uno dei metodi per garantire una pianificazione accurata. Nonostante il gran numero di metodi sviluppati, perseguono tutti lo stesso obiettivo: prevedere gli eventi che si verificheranno in futuro per tenerne conto durante lo sviluppo di piani e strategie per lo sviluppo dell'azienda.
La società moderna ha costantemente bisogno di previsioni. Ad esempio, per formulare la giusta politica, i membri del governo devono prevedere i livelli di disoccupazione, inflazione, produzione industriale, imposte sul reddito personale e aziendale. Per determinare le esigenze di attrezzature e personale, i direttori delle compagnie aeree devono prevedere correttamente il volume del viaggio aereo. Per creare abbastanza dormitori, gli amministratori di college o università vogliono sapere quanti studenti saranno ammessi al loro istituto nel prossimo anno.
Esistono due approcci generalmente accettati alla previsione: qualitativo e quantitativo. I metodi di previsione qualitativa sono particolarmente importanti quando i dati quantitativi non sono disponibili per il ricercatore. In genere, questi metodi sono altamente soggettivi. Se sono disponibili statistiche sulla storia dell'oggetto di studio, dovrebbero essere utilizzati metodi di previsione quantitativi. Questi metodi consentono di prevedere lo stato di un oggetto nel futuro in base ai dati sul suo passato. I metodi di previsione quantitativa si dividono in due categorie: analisi delle serie temporali e metodi di analisi causale.
serie temporaliè un insieme di dati numerici acquisiti in periodi di tempo consecutivi. L'analisi delle serie temporali consente di prevedere il valore di una variabile numerica in base ai suoi valori passati e presenti. Ad esempio, i prezzi giornalieri delle azioni alla Borsa di New York formano una serie temporale. Un altro esempio di una serie temporale è l'IPC mensile, il prodotto interno lordo trimestrale e il fatturato annuo di un'azienda.
Metodi per l'analisi delle relazioni causali consentono di determinare quali fattori influenzano i valori della variabile prevista. Questi includono metodi di analisi di regressione multipla con variabili in ritardo, modellazione econometrica, analisi di indicatori anticipatori, metodi di analisi di indici di diffusione e altri indicatori economici. Parleremo solo di metodi di previsione basati sull'analisi del tempo. NS x righe.
Componenti del modello temporale moltiplicativo classico NS x righe
Il presupposto principale alla base dell'analisi delle serie temporali è il seguente: i fattori che influenzano l'oggetto in esame nel presente e nel passato lo influenzeranno in futuro. Pertanto, gli obiettivi principali dell'analisi delle serie temporali sono identificare ed evidenziare i fattori importanti per la previsione. Per raggiungere questo obiettivo, sono stati sviluppati molti modelli matematici progettati per studiare le fluttuazioni dei componenti inclusi nel modello delle serie temporali. Probabilmente il più comune è il classico modello moltiplicativo per dati annuali, trimestrali e mensili. Per dimostrare il classico modello di serie temporale moltiplicativa, considerare i dati sugli utili effettivi di Wm.Wrigley Jr. Società per il periodo 1982-2001 (Fig. 1).
Riso. 1. Un grafico del reddito lordo effettivo di Wm.Wrigley Jr. Azienda (milioni di dollari a prezzi correnti) dal 1982 al 2001
Come puoi vedere, negli ultimi 20 anni, il reddito lordo effettivo dell'azienda ha registrato una tendenza al rialzo. Questa tendenza a lungo termine è chiamata tendenza. Tendenza non è l'unico componente della serie storica. Inoltre, i dati hanno componenti cicliche e irregolari. ciclico componente descrive le fluttuazioni dei dati verso l'alto e verso il basso, spesso in correlazione con i cicli economici. La sua lunghezza varia dai 2 ai 10 anni. Anche l'intensità, o ampiezza, della componente ciclica non è costante. In alcuni anni, i dati possono essere superiori al valore previsto dal trend (cioè essere in prossimità del picco del ciclo), e in altri anni - inferiori (cioè essere alla fine del ciclo). Qualsiasi dato osservabile che non giace sulla curva di tendenza e non obbedisce a una relazione ciclica è chiamato irregolare o componenti casuali... Se i dati vengono registrati giornalmente o trimestralmente, sorge una componente aggiuntiva chiamata di stagione... Tutti i componenti delle serie temporali tipiche per le applicazioni economiche sono mostrati in Fig. 2.

Riso. 2. Fattori che influenzano le serie temporali
Il classico modello delle serie temporali moltiplicative afferma che qualsiasi valore osservato è il prodotto dei componenti elencati. Se i dati sono annuali, osservazione sìio corrispondente io-esimo anno, è espresso dall'equazione:
(1) e io = T io* C io* io sono
dove T io- valore di tendenza, C io io-esimo anno, io sono io esimo anno.
Se i dati vengono misurati mensilmente o trimestralmente, l'osservazione e io corrispondente al periodo i-esimo è espresso dall'equazione:
(2) Y io = T io * S io * C io * io i
dove T io- valore di tendenza, S ioè il valore della componente stagionale in io-esimo periodo, C ioè il valore della componente ciclica in io-esimo periodo, io sonoè il valore della componente casuale in io-esimo periodo.
Nella prima fase dell'analisi delle serie temporali, i dati vengono tracciati e viene rivelata la loro dipendenza dal tempo. Innanzitutto, è necessario scoprire se c'è un aumento o una diminuzione a lungo termine dei dati (ovvero trend) o se la serie temporale fluttua attorno a una linea orizzontale. Se non c'è tendenza, è possibile utilizzare la media mobile o il livellamento esponenziale per livellare i dati.
Livellamento delle serie temporali annuali
Abbiamo menzionato Cabot Corporation nella sceneggiatura. Con sede a Boston, Massachusetts, è specializzata nella produzione e vendita di prodotti chimici, materiali da costruzione, prodotti della chimica fine, semiconduttori e gas naturale liquefatto. L'azienda ha 39 stabilimenti in 23 paesi. La società ha un valore di mercato di circa 1,87 miliardi di dollari e le sue azioni sono quotate alla Borsa di New York con l'acronimo CBT. I ricavi della società per il periodo specificato sono mostrati in Fig. 3.

Riso. 3. Ricavi di Cabot Corporation nel 1982-2001 (miliardi di dollari)
Come puoi vedere, la tendenza al rialzo a lungo termine del reddito è oscurata da un gran numero di fluttuazioni. Pertanto, l'analisi visiva del grafico non ci consente di affermare che i dati sono di tendenza. In tali situazioni possono essere utilizzate tecniche di livellamento della media mobile o esponenziale.
Medie mobili. Il metodo della media mobile è molto soggettivo e dipende dalla durata del periodo l selezionato per il calcolo delle medie. Per escludere fluttuazioni cicliche, la durata del periodo deve essere un multiplo intero della durata media del ciclo. Medie mobili per un periodo di durata selezionato l, formano una sequenza di medie calcolata per sequenze di lunghezza l... Le medie mobili sono indicate dai simboli MA (L).
Supponiamo di voler calcolare le medie mobili quinquennali dai dati misurati nel corso di n= 11 anni. Nella misura in cui l= 5, le medie mobili quinquennali formano una sequenza di medie calcolate da cinque valori consecutivi della serie temporale. La prima delle medie mobili quinquennali si calcola sommando i primi cinque anni e poi dividendo per cinque:
![]()
La seconda media mobile quinquennale viene calcolata sommando i dati per gli anni da 2 a 6 e quindi dividendo per cinque:
![]()
Questo processo continua finché non viene calcolata una media mobile per gli ultimi cinque anni. Lavorando con i dati annuali, si dovrebbe assumere il numero l(la lunghezza del periodo selezionato per il calcolo delle medie mobili) è dispari. In questo caso, è impossibile calcolare le medie mobili per il primo ( l- 1) / 2 e ultimo ( l- 12 anni. Pertanto, quando si lavora con medie mobili quinquennali, non è possibile eseguire calcoli per i primi due e gli ultimi due anni. L'anno per il quale viene calcolata la media mobile deve trovarsi a metà di un periodo di lunghezza l... Se n= 11, a l= 5, la prima media mobile deve corrispondere al terzo anno, la seconda al quarto e l'ultima al nono. Nella fig. 4 mostra i grafici delle medie mobili a 3 e 7 anni calcolate per i guadagni di Cabot Corporation dal 1982 al 2001.

Riso. 4. Grafici delle medie mobili a 3 e 7 anni, calcolati per il reddito della società Cabot Corporation
Si noti che i valori osservati per il primo e l'ultimo anno vengono ignorati quando si calcolano le medie mobili a 3 anni. Allo stesso modo, quando si calcolano le medie mobili a sette anni, non ci sono risultati per il primo e gli ultimi tre anni. Inoltre, le medie mobili a 7 anni levigano le serie temporali molto più di quelle a 3 anni. Questo perché la media mobile a 7 anni ha un periodo più lungo. Sfortunatamente, più lungo è il periodo, meno medie mobili possono essere calcolate e presentate sul grafico. Pertanto, non è consigliabile scegliere più di sette anni per il calcolo delle medie mobili, poiché troppi punti cadranno dall'inizio e dalla fine del grafico, il che distorcerà la forma della serie temporale.
Livellamento esponenziale. Per identificare le tendenze a lungo termine che caratterizzano i cambiamenti dei dati, ad eccezione delle medie mobili, viene utilizzato il metodo del livellamento esponenziale. Questo metodo consente anche di fare previsioni a breve termine (entro un periodo), quando l'esistenza di tendenze a lungo termine è dubbia. Per questo motivo, il metodo di livellamento esponenziale ha un vantaggio significativo rispetto al metodo della media mobile.
Il metodo di livellamento esponenziale prende il nome da una sequenza di medie mobili ponderate esponenzialmente. Ciascun valore in questa sequenza dipende da tutti i valori osservati in precedenza. Un altro vantaggio del metodo di livellamento esponenziale rispetto al metodo della media mobile è che quando si utilizza quest'ultimo, alcuni valori vengono scartati. Con il livellamento esponenziale, i pesi assegnati ai valori osservati diminuiscono nel tempo, quindi dopo aver eseguito il calcolo, i valori più comuni vengono pesati di più e i valori meno frequenti. Nonostante l'enorme quantità di calcoli, Excel consente di implementare il metodo di livellamento esponenziale.
Un'equazione che appiattisce una serie temporale su un periodo di tempo arbitrario io, contiene tre membri: il valore osservato corrente sìio, appartenente alla serie storica, il precedente valore livellato esponenzialmente Eio –1 e peso assegnato W.
(3) E 1 = Y 1 E i = WY i + (1 - W) E i – 1, i = 2, 3, 4,…
dove Eio- il valore della serie esponenzialmente livellata, calcolato per io-esimo periodo, E io –1 Il valore di una serie livellata esponenzialmente è calcolato per ( io- 1) -vai periodo, e io- il valore osservato della serie storica in io-esimo periodo, W- peso soggettivo, o coefficiente di livellamento (0< W < 1).
La scelta del fattore di livellamento, ovvero del peso assegnato ai componenti della serie, è fondamentale perché incide direttamente sul risultato. Purtroppo questa scelta è alquanto soggettiva. Se il ricercatore vuole solo escludere fluttuazioni cicliche o casuali indesiderate dalle serie temporali, dovrebbero essere scelti valori piccoli W(vicino allo zero). D'altra parte, se si utilizza una serie storica per la previsione, è necessario scegliere un peso elevato W(vicino a uno). Nel primo caso si manifestano chiaramente tendenze a lungo termine nelle serie storiche. Nel secondo caso, l'accuratezza delle previsioni a breve termine aumenta (Fig. 5).

Riso. 5 Grafici di serie temporali esponenzialmente livellate (W = 0,50 e W = 0,25) per i dati sugli utili di Cabot Corporation dal 1982 al 2001; formule di calcolo vedi file Excel
Valore livellato esponenzialmente ottenuto per io-esimo intervallo di tempo può essere utilizzato come stima del valore previsto in ( io+1) -esimo intervallo:
![]()
Prevedere i ricavi di Cabot Corporation nel 2002 sulla base di una serie temporale livellata esponenzialmente corrispondente al peso W= 0,25, può essere utilizzato il valore livellato calcolato per il 2001. Dalla fig. La Figura 5 mostra che questo valore è pari a $ 1.651,0 milioni. Quando i dati sui ricavi dell'azienda nel 2002 diventano disponibili, possiamo applicare l'equazione (3) e prevedere il livello dei ricavi nel 2003 utilizzando il valore livellato dei ricavi nel 2002:
Pacchetto di analisi Excel è in grado di tracciare il livellamento esponenziale con un clic. Scorri il menu Dati → Analisi dei dati e seleziona l'opzione Livellamento esponenziale(fig. 6). Nella finestra aperta Livellamento esponenziale impostare i parametri. Sfortunatamente, la procedura ti consente di costruire solo una riga levigata, quindi se vuoi giocare con il parametro W, ripetere la procedura.

Riso. 6. Tracciare il livellamento esponenziale utilizzando il pacchetto di analisi
Andamento e previsione dei minimi quadrati
Tra le componenti delle serie storiche, la tendenza è quella più studiata. È il trend che permette di fare previsioni a breve e lungo termine. Per identificare una tendenza a lungo termine in una serie temporale, di solito viene disegnato un grafico su cui vengono tracciati i dati osservati (valori della variabile dipendente) sull'asse verticale e intervalli di tempo (valori della variabile indipendente) sono tracciati sull'asse orizzontale. In questa sezione, descriviamo la procedura per rilevare trend lineari, quadratici ed esponenziali utilizzando il metodo dei minimi quadrati.
Modello di tendenza lineareè il modello più semplice utilizzato per la previsione: e io = β 0 + β 1 X io + io. Equazione di tendenza lineare:
![]()
Per un dato livello di significatività α, l'ipotesi nulla è rifiutata se il test T-statistiche superiori al livello critico superiore o inferiore al livello critico inferiore T-distribuzioni. In altre parole, la regola di decisione è formulata come segue: se T > Ttu o T < t L, ipotesi nulla H 0 viene rifiutata, altrimenti l'ipotesi nulla non viene rifiutata (Fig. 14).

Riso. 14. Aree di rigetto dell'ipotesi per il test bilaterale della significatività del parametro autoregressivo un r avere l'ordine più alto
Se l'ipotesi nulla ( un r= 0) non rifiuta, il che significa che il modello selezionato contiene troppi parametri. Il criterio consente di scartare il membro anziano del modello e valutare il modello autoregressivo dell'ordine p – 1... Questa procedura dovrebbe essere continuata fino all'ipotesi nulla H 0 non sarà rifiutato.
- Seleziona l'ordine R il modello autoregressivo stimato, tenendo conto che T- il criterio di significatività ha n–2p – 1 gradi di libertà.
- Forma una sequenza di variabili R"Lagging" in modo che la prima variabile sia in ritardo di un intervallo di tempo, la seconda di due e così via. L'ultimo valore dovrebbe essere ritardato di R intervalli di tempo (vedi Fig. 15).
- Applicare Pacchetto di analisi Excel per calcolare un modello di regressione contenente tutto R valori di serie temporali ritardati.
- Stimare la significatività del parametro A R di prim'ordine: a) se l'ipotesi nulla è respinta, all R parametri; b) se l'ipotesi nulla non viene rifiutata, scartare R-esima variabile e ripetere i passaggi 3 e 4 per un nuovo modello che include p – 1 parametro. La convalida della significatività del nuovo modello si basa su T-criteria, il numero di gradi di libertà è determinato dal nuovo numero di parametri.
- Ripetere i passaggi 3 e 4 fino a quando il termine senior del modello autoregressivo diventa statisticamente significativo.
Per dimostrare la modellizzazione autoregressiva, torniamo all'analisi delle serie storiche dei guadagni reali della società Wm. Wrigley Jr. Nella fig. 15 mostra i dati necessari per costruire modelli autoregressivi del primo, secondo e terzo ordine. Tutte le colonne di questa tabella sono necessarie per creare un modello di terzo ordine. Quando si costruisce un modello autoregressivo di secondo ordine, l'ultima colonna viene ignorata. Quando si costruisce un modello autoregressivo di primo ordine, le ultime due colonne vengono ignorate. Pertanto, quando si costruiscono modelli autoregressivi del primo, secondo e terzo ordine, rispettivamente uno, due e tre sono escluse da 20 variabili.

La scelta del modello autoregressivo più accurato inizia con un modello di terzo ordine. Per un lavoro corretto Pacchetto di analisi seguito come intervallo di input sì specificare l'intervallo B5: B21 e l'intervallo di input per NS- DO5: MI21. I dati dell'analisi sono mostrati in Fig. 16.

Verificare il significato del parametro un 3 avendo l'ordine più alto. La sua valutazione un 3è –0,006 (cella C20 in Figura 16) e l'errore standard è 0,326 (cella D20). Per verificare le ipotesi H 0: A 3 = 0 e H 1: A 3 ≠ 0, calcoliamo T-statistiche:

T-criteri con n – 2p – 1 = 20–2 * 3–1 = 13 gradi di libertà sono uguali: t L= STUDENTE.OBR (0.025; 13) = –2.160; t U= STUDENTE.OBR (0.975,13) = +2.160. Da -2.160< T = –0,019 < +2,160 и R= 0,985> α = 0,05, ipotesi nulla H 0 non può essere rifiutato. Pertanto, il parametro del terzo ordine non ha alcun significato statistico nel modello autoregressivo e dovrebbe essere rimosso.
Ripetiamo l'analisi per il modello autoregressivo del secondo ordine (Fig. 17). Stima del parametro di ordine più alto, un 2= –0.205 e il suo errore standard è 0.276. Per verificare le ipotesi H 0: A 2 = 0 e H 1: A 2 ≠ 0, calcoliamo T-statistiche:


Al livello di significatività α = 0,05, i valori critici dei due lati T-criteri con n – 2p – 1 = 20–2 * 2-1 = 15 gradi di libertà sono uguali: t L= STUDENTE.OBR (0.025; 15) = –2.131; t U= STUDENTE.OBR (0.975; 15) = +2.131. Da –2.131< T = –0,744 < –2,131 и R= 0,469> α = 0,05, ipotesi nulla H 0 non può essere rifiutato. Pertanto, il parametro del secondo ordine non è statisticamente significativo e dovrebbe essere rimosso dal modello.
Ripetiamo l'analisi per il modello autoregressivo del primo ordine (Fig. 18). Stima del parametro di ordine più alto, un 1= 1,024 e il suo errore standard è 0,039. Per verificare le ipotesi H 0: A 1 = 0 e H 1: A 1 ≠ 0, calcoliamo T-statistiche:


Al livello di significatività α = 0,05, i valori critici dei due lati T-criteri con n – 2p – 1 = 20–2 * 1-1 = 17 gradi di libertà sono uguali: t L= STUDENTE.OBR (0.025; 17) = –2.110; t U= STUDENTE.OBR (0.975; 17) = +2.110. Da -2.110< T = 26,393 < –2,110 и R = 0,000 < α = 0,05, нулевую гипотезу H 0 dovrebbe essere rifiutato. Pertanto, il parametro del primo ordine è statisticamente significativo e non può essere rimosso dal modello. Quindi, il modello autoregressivo del primo ordine è la migliore approssimazione dei dati originali. Utilizzo di stime uno 0 = 18,261, un 1= 1.024 e il valore della serie storica dell'ultimo anno - Y 20 = 1 371.88, si può prevedere il valore del reddito reale dell'impresa Wm. Wrigley Jr. Azienda nel 2002:
Scegliere un modello di previsione adeguato
Sono stati descritti sopra sei metodi per prevedere i valori delle serie temporali: modelli di trend lineari, quadratici ed esponenziali e modelli autoregressivi di primo, secondo e terzo ordine. Esiste un modello ottimale? Quale dei sei modelli descritti dovrebbe essere utilizzato per prevedere il valore delle serie temporali? Di seguito sono elencati quattro principi che dovrebbero guidare la scelta di un modello di previsione adeguato. Questi principi si basano su stime dell'accuratezza dei modelli. Si presume che i valori della serie temporale possano essere previsti studiando i suoi valori precedenti.
Principi per la scelta dei modelli di previsione:
- Eseguire l'analisi dei residui.
- Stimare l'errore residuo utilizzando le differenze al quadrato.
- Stimare l'errore residuo utilizzando le differenze assolute.
- Lasciati guidare dal principio di economia.
Analisi del residuo. Ricordiamo che il residuo è la differenza tra il valore previsto e il valore osservato. Dopo aver costruito un modello per le serie temporali, si dovrebbero calcolare i residui per ciascuno di n intervalli. Come mostrato in fig. 19, pannello A, se il modello è adeguato, i residui rappresentano una componente casuale della serie storica e sono quindi distribuiti irregolarmente. D'altra parte, come mostrato nei restanti pannelli, se il modello non è adeguato, i residui possono avere una relazione sistematica che non tiene conto né dell'andamento (pannello B), né ciclico (pannello C), né della stagionalità componente (pannello D).

Riso. 19. Analisi dei residui
Misura degli errori residui assoluti e quadratici medi. Se l'analisi dei residui non consente di determinare un unico modello adeguato, è possibile utilizzare altri metodi basati su una stima dell'entità dell'errore residuo. Sfortunatamente, non c'è consenso tra gli statistici sulla migliore stima degli errori residui dei modelli utilizzati per la previsione. In base al principio dei minimi quadrati, puoi prima eseguire un'analisi di regressione e calcolare l'errore standard della stima S XY... Quando si analizza un modello specifico, questo valore è la somma dei quadrati delle differenze tra i valori effettivi e quelli previsti delle serie temporali. Se il modello si adatta perfettamente ai valori delle serie temporali nei momenti precedenti, l'errore standard della stima è zero. D'altra parte, se il modello approssima male i valori delle serie temporali in momenti precedenti, l'errore standard della stima è grande. Quindi, analizzando l'adeguatezza di più modelli, si può scegliere un modello che abbia un errore standard minimo della stima S XY.
Il principale svantaggio di questo approccio è l'esagerazione degli errori nella previsione dei valori individuali. In altre parole, qualsiasi grande differenza tra le quantità sìio e Ŷ io quando si calcola la somma degli errori al quadrato, l'SSE è al quadrato, cioè aumenta. Per questo motivo, molti statistici preferiscono utilizzare la deviazione media assoluta (MAD) per valutare l'adeguatezza di un modello di previsione:

Quando si analizzano modelli specifici, il valore MAD è il valore medio dei valori assoluti delle differenze tra i valori effettivi e previsti delle serie temporali. Se il modello si adatta perfettamente ai valori delle serie temporali nei momenti precedenti, la deviazione media assoluta è zero. D'altra parte, se il modello approssima male tali valori di serie temporali, la deviazione media assoluta è grande. Quindi, analizzando l'adeguatezza di più modelli, è possibile selezionare un modello che abbia la minima deviazione media assoluta.
Il principio di economia. Se l'analisi degli errori standard delle stime e delle deviazioni medie assolute non consente di determinare il modello ottimale, è possibile utilizzare il quarto metodo, basato sul principio di economia. Questo principio afferma che il più semplice dovrebbe essere scelto tra diversi modelli uguali.
Dei sei modelli di previsione discussi in questo capitolo, i più semplici sono i modelli di regressione lineare e quadratica, nonché il modello autoregressivo del primo ordine. Il resto dei modelli è molto più complesso.
Confronto di quattro metodi di previsione. Per illustrare il processo di scelta del modello ottimo, torniamo alla serie storica costituita dai valori del reddito reale della società Wm. Wrigley Jr. Società. Confrontiamo quattro modelli: modelli lineari, quadratici, esponenziali e autoregressivi del primo ordine. (I modelli autoregressivi di secondo e terzo ordine migliorano solo leggermente l'accuratezza della previsione dei valori di una determinata serie temporale, quindi possono essere ignorati.) 20 mostra i grafici dei residui costruiti analizzando quattro metodi di previsione utilizzando Pacchetto di analisi Eccellere. Fai attenzione quando trai conclusioni da questi grafici, poiché la serie temporale contiene solo 20 punti. Per i metodi di costruzione, vedere il foglio corrispondente nel file Excel.

Riso. 20. Grafici dei residui, costruiti nell'analisi di quattro metodi di previsione utilizzando Pacchetto di analisi Eccellere
Nessun modello diverso dal modello autoregressivo del primo ordine tiene conto della componente ciclica. È questo modello che approssima le osservazioni meglio di altri ed è caratterizzato dalla struttura meno sistematica. Quindi, l'analisi dei residui di tutti e quattro i metodi ha mostrato che il modello autoregressivo del primo ordine è il migliore e che i modelli lineare, quadratico ed esponenziale hanno una precisione inferiore. Per convincersene, confrontiamo i valori degli errori residui di questi metodi (Fig. 21). Puoi familiarizzare con il metodo di calcolo aprendo il file Excel. Nella fig. 21 sono valori reali e io(altoparlante Reddito reale), valori previsti Ŷ io così come gli avanzi eio per ciascuno dei quattro modelli. Inoltre, i valori mostrati sono SYX e PAZZO... Per tutti e quattro i modelli, le quantità SYX e PAZZO piu 'o meno lo stesso. Il modello esponenziale è relativamente inferiore, mentre i modelli lineare e quadratico sono superiori in accuratezza. Come previsto, i valori più piccoli SYX e PAZZO ha un modello autoregressivo del primo ordine.

Riso. 21. Confronto di quattro metodi di previsione utilizzando gli indicatori S YX e MAD
Avendo scelto uno specifico modello di previsione, è necessario monitorare da vicino ulteriori variazioni nelle serie storiche. Tra l'altro, tale modello viene creato per prevedere correttamente i valori delle serie temporali in futuro. Sfortunatamente, tali modelli di previsione tengono in scarsa considerazione i cambiamenti nella struttura delle serie temporali. È assolutamente necessario confrontare non solo l'errore residuo, ma anche l'accuratezza della previsione dei valori futuri delle serie temporali ottenute con l'aiuto di altri modelli. Dopo aver misurato il nuovo valore sìio nell'intervallo di tempo osservato, deve essere immediatamente confrontato con il valore previsto. Se la differenza è troppo grande, il modello di previsione dovrebbe essere rivisto.
Tempo di previsione NS x serie basate su dati stagionali
Finora abbiamo studiato una serie temporale composta da dati annuali. Tuttavia, molte serie temporali sono composte da quantità misurate su base trimestrale, mensile, settimanale, giornaliera e persino oraria. Come mostrato in fig. 2, se i dati sono misurati mensilmente o trimestralmente, va considerata la componente stagionale. In questa sezione, esamineremo i metodi per prevedere i valori di tali serie temporali.
Lo scenario all'inizio del capitolo si riferiva a Wal-Mart Stores, Inc. La società ha una capitalizzazione di mercato di 229 miliardi di dollari e le sue azioni sono quotate alla Borsa di New York con l'acronimo WMT. L'anno finanziario della società termina il 31 gennaio, quindi il quarto trimestre del 2002 include novembre e dicembre 2001 e gennaio 2002. La serie storica dei ricavi trimestrali della società è mostrata in Fig. 22.

Riso. 22. Wal-Mart Stores, Inc. Ricavi trimestrali (milioni di dollari)
Per serie trimestrali come questa, il modello moltiplicativo classico, oltre alle componenti trend, cicliche e casuali, contiene una componente stagionale: e io = T io* S io* C io* io sono
Previsione delle mestruazioni e del tempo NS x righe utilizzando il metodo dei minimi quadrati. Il modello di regressione con una componente stagionale si basa su un approccio combinato. Per calcolare l'andamento viene utilizzato il metodo dei minimi quadrati descritto in precedenza e per tenere conto della componente stagionale - la variabile categoriale (per maggiori dettagli, vedere la sezione Modelli di regressione fittizia ed effetti di interazione). Un modello esponenziale viene utilizzato per approssimare le serie temporali con componenti stagionali. In un modello che approssima una serie temporale trimestrale, avevamo bisogno di tre variabili fittizie per tenere conto di quattro trimestri Q 1, Q2 e Q 3 e nel modello per una serie storica mensile, 12 mesi sono rappresentati utilizzando 11 variabili fittizie. Poiché questi modelli utilizzano la variabile log e io, ma no e io, per calcolare i coefficienti di regressione reali, è necessario eseguire la trasformazione inversa.
Per illustrare il processo di costruzione di un modello di serie temporali trimestrali, torniamo ai guadagni di Wal-Mart. I parametri del modello esponenziale ottenuti usando Pacchetto di analisi Excel sono mostrati in Fig. 23.

Riso. 23. Analisi di regressione degli utili trimestrali di Wal-Mart Stores, Inc.
Si può vedere che il modello esponenziale approssima abbastanza bene i dati originali. Coefficiente di correlazione mista R 2 è 99,4% (celle J5), il coefficiente corretto di correlazione mista è 99,3% (celle J6), test F-statistiche - 1.333,51 (celle M12), e R-valore è 0,0000. Ad un livello di significatività di α = 0,05, ogni coefficiente di regressione in un classico modello di serie temporali moltiplicativa è statisticamente significativo. Applicando ad essi l'operazione di potenziamento si ottengono i seguenti parametri:

Probabilità ![]() sono interpretati come segue.
sono interpretati come segue.
Utilizzo dei coefficienti di regressione b io, puoi prevedere il reddito ricevuto dall'azienda in un trimestre specifico. Ad esempio, supponiamo il fatturato dell'azienda per il quarto trimestre del 2002 ( Xio = 35):
registro = B 0 + B 1 NSio = 4,265 + 0,016*35 = 4,825
= 10 4,825 = 66 834
Pertanto, secondo le previsioni nel quarto trimestre del 2002, l'azienda avrebbe dovuto ricevere un fatturato pari a 67 miliardi di dollari (difficilmente si dovrebbe fare una previsione al milione più vicino). Al fine di estendere la previsione per un periodo di tempo al di fuori della serie storica, ad esempio per il primo trimestre del 2003 ( Xio = 36, Q 1= 1), è necessario eseguire i seguenti calcoli:
tronco d'albero io = b 0 + b 1NSio + b2Q1 = 4,265 + 0,016*36 – 0,093*1 = 4,748
10 4,748 = 55 976
Indici
Gli indici sono utilizzati come indicatori che rispondono ai cambiamenti della situazione economica o dell'attività commerciale. Esistono molti tipi di indici, come indici di prezzo, indici quantitativi, indici di valore e indici sociologici. In questa sezione, prenderemo in considerazione solo l'indice dei prezzi. Indice- il valore di un indicatore economico (o di un gruppo di indicatori) in un determinato momento, espresso come percentuale del suo valore nel momento base.
Indice dei prezzi. Un semplice indice dei prezzi riflette la variazione percentuale del prezzo di un prodotto (o gruppo di prodotti) in un determinato periodo di tempo rispetto al prezzo di quel prodotto (o gruppo di prodotti) in un determinato momento nel passato. Quando si calcola l'indice dei prezzi, prima di tutto, è necessario selezionare un intervallo di tempo di base, un intervallo di tempo nel passato con cui verranno effettuati i confronti. Quando si sceglie un periodo base per un indice specifico, i periodi di stabilità economica sono preferibili ai periodi di ripresa economica o recessione. Inoltre, la linea di base non dovrebbe essere troppo distante nel tempo, in modo che i risultati del confronto non siano influenzati troppo fortemente dai cambiamenti nella tecnologia e nelle abitudini dei consumatori. L'indice dei prezzi è calcolato utilizzando la formula:

dove io sono- indice dei prezzi in io-il mio orecchio, Rio- prezzo in io-il mio orecchio, basi R- prezzo nell'anno base.
L'indice dei prezzi è la variazione percentuale del prezzo di un prodotto (o di un gruppo di prodotti) in un determinato periodo di tempo rispetto al prezzo di un prodotto in un momento base. Ad esempio, si consideri l'indice dei prezzi della benzina senza piombo negli Stati Uniti tra il 1980 e il 2002 (Figura 24). Per esempio:


Riso. 24. Prezzo di un gallone di benzina senza piombo e indice dei prezzi semplice negli Stati Uniti dal 1980 al 2002 (anni base - 1980 e 1995)
Così, nel 2002 il prezzo della benzina senza piombo negli Stati Uniti è stato del 4,8% in più rispetto al 1980. Analisi fig. 24 mostra che l'indice dei prezzi nel 1981 e 1982. era superiore all'indice dei prezzi nel 1980, e quindi fino al 2000 non superava il livello base. Dal momento che il 1980 è selezionato come periodo di base, probabilmente ha senso scegliere un anno più vicino, ad esempio il 1995. La formula per ricalcolare l'indice rispetto al nuovo periodo di tempo di base è:

dove ionuovo- nuovo indice dei prezzi, iovecchio- vecchio indice dei prezzi, ionuovo base - il valore dell'indice dei prezzi nel nuovo anno base quando si calcola per il vecchio anno base.
Supponiamo che il 1995 sia selezionato come nuova base. Usando la formula (10), otteniamo un nuovo indice dei prezzi per il 2002:
Quindi, nel 2002, la benzina senza piombo negli Stati Uniti costava il 13,9% in più rispetto al 1995.
Indici di prezzo compositi non ponderati. Nonostante l'indice dei prezzi per ogni singolo prodotto sia di indubbio interesse, più importante è l'indice dei prezzi per un gruppo di beni, che consente di valutare il costo e il tenore di vita di un gran numero di consumatori. L'indice dei prezzi composito non ponderato definito dalla formula (11) assegna uguale peso a ciascuna singola merce. Un indice dei prezzi composito riflette la variazione percentuale del prezzo di un gruppo di beni (spesso chiamato paniere di beni) in un dato periodo di tempo rispetto al prezzo di quel gruppo di beni in un punto base nel tempo.

dove T io- numero articolo (1, 2, ..., n), n- il numero di merci del gruppo considerato, - la somma dei prezzi per ciascuno dei n merci in tempo T, è la somma dei prezzi per ciascuno di n merci nel periodo di tempo zero, è il valore dell'indice composito non ponderato nel periodo di tempo T.
Nella fig. 25 mostra i prezzi medi di tre tipi di frutta per il periodo dal 1980 al 1999. Per calcolare l'indice dei prezzi composito non ponderato in diversi anni, viene utilizzata la formula (11), considerando il 1980 come anno base.
Quindi, nel 1999 il prezzo totale di un chilo di mele, un chilo di banane e un chilo di arance era del 59,4% superiore al prezzo totale di questi frutti nel 1980.

Riso. 25. Prezzi (in dollari) per tre tipi di frutta e un indice dei prezzi composito non ponderato
L'indice dei prezzi composito non ponderato esprime le variazioni dei prezzi per un intero gruppo di beni nel tempo. Sebbene questo indice sia facile da calcolare, presenta due distinti svantaggi. Innanzitutto, quando si calcola questo indice, tutti i tipi di beni sono considerati ugualmente importanti, quindi i beni costosi acquisiscono un'influenza non necessaria sull'indice. In secondo luogo, non tutte le materie prime vengono consumate allo stesso modo, quindi le variazioni di prezzo per le materie prime a basso consumo sono troppo forti per l'indice non ponderato.
Indici di prezzo compositi ponderati. A causa delle carenze degli indici dei prezzi non ponderati, sono preferibili gli indici dei prezzi ponderati, tenendo conto delle differenze nei prezzi e nei livelli di consumo dei beni che formano il paniere dei consumatori. Esistono due tipi di indici di prezzo compositi ponderati. Indice dei prezzi di Lapeyre definito dalla formula (12) utilizza i livelli di consumo nell'anno base. L'indice dei prezzi composito ponderato tiene conto dei livelli di consumo dei beni che compongono il paniere dei consumatori assegnando un certo peso a ciascun bene.

dove T- periodo (0, 1, 2, ...), io- numero articolo (1, 2, ..., n), n io nell'intervallo di tempo zero, è il valore dell'indice di LaPeyre nell'intervallo di tempo T.
I calcoli dell'indice di Lapeyre sono mostrati in Fig. 26; Il 1980 viene utilizzato come anno di base.

Riso. 26. Prezzi (in dollari), quantità (consumo in libbre pro capite) di tre tipi di frutta e indice LaPeyre
Quindi, l'indice di Lapeyre nel 1999 è 154,2. Ciò indica che nel 1999 questi tre tipi di frutta erano più costosi del 54,2% rispetto al 1980. Si noti che questo indice è inferiore all'indice non ponderato di 159,4, poiché i prezzi delle arance - il frutto meno consumato - sono aumentati più di mele e banane. In altre parole, poiché i prezzi dei frutti più consumati sono aumentati meno dei prezzi delle arance, l'indice di Lapeyre è inferiore all'indice composito non ponderato.
Indice dei prezzi di Paasche utilizza i livelli di consumo del prodotto nel periodo di tempo corrente, non di base. Di conseguenza, l'indice di Paasche riflette più accuratamente il costo totale del consumo di beni in un dato momento. Tuttavia, questo indice presenta due svantaggi significativi. Innanzitutto, di solito è difficile determinare i livelli di consumo attuali. Per questo motivo, molti indici popolari utilizzano l'indice LaPeyre piuttosto che l'indice Paasche. In secondo luogo, se il prezzo di un particolare prodotto nel paniere dei consumatori aumenta notevolmente, gli acquirenti riducono il consumo per necessità e non a causa di un cambiamento nei gusti. L'indice di Paasche è calcolato con la formula:

dove T- periodo (0, 1, 2, ...), io- numero articolo (1, 2, ..., n), n- il numero di prodotti del gruppo considerato, - il numero di unità del prodotto io nell'intervallo di tempo zero, è il valore dell'indice Paasche nell'intervallo di tempo T.
I calcoli dell'indice di Paasche sono mostrati in Fig. 27; Il 1980 viene utilizzato come anno di base.

Riso. 27. Prezzi (in dollari), quantità (consumo in libbre pro capite) di tre tipi di frutta e indice Paasche
Quindi, l'indice Paasche nel 1999 è 147,0. Ciò indica che nel 1999 questi tre tipi di frutta erano più costosi del 47,0% rispetto al 1980.
Alcuni indici di prezzo popolari. Diversi indici di prezzo sono utilizzati negli affari e nell'economia. Il più popolare è l'indice dei prezzi al consumo (CPI). Ufficialmente, questo indice è chiamato CPI-U per sottolineare che è calcolato per le città (urbane), sebbene di solito sia chiamato semplicemente CPI. Questo indice è pubblicato mensilmente dal Bureau of Labor Statistics degli Stati Uniti come strumento principale per misurare il costo della vita negli Stati Uniti. L'indice dei prezzi al consumo è composto e ponderato con il metodo Lapeyre. Viene calcolato utilizzando i prezzi di 400 tra i prodotti più comunemente consumati, i tipi di abbigliamento, i trasporti, i servizi medici e le utenze. Al momento, nel calcolo di questo indice, viene utilizzato come base il periodo 1982-1984. (fig. 28). Una funzione importante del CPI è il suo utilizzo come deflatore. Il CPI viene utilizzato per convertire i prezzi effettivi in prezzi reali moltiplicando ciascun prezzo per un fattore 100 / CPI. I calcoli mostrano che negli ultimi 30 anni il tasso di inflazione medio annuo negli Stati Uniti è stato del 2,9%.

Riso. 28. Dinamica del prezzo dell'indice al consumo; vedere il file Excel per tutti i dettagli
Un altro importante indice dei prezzi pubblicato dal Bureau of Labor Statistics è l'indice dei prezzi alla produzione (PPI). Il PPI è un indice composito ponderato che utilizza il metodo Lapeyre per stimare la variazione dei prezzi dei beni venduti dai loro produttori. Il PPI è l'indicatore principale per il CPI. In altre parole, un aumento del PPI porta ad un aumento del CPI e, viceversa, una diminuzione del PPI porta a una diminuzione del CPI. Gli indici finanziari come il Dow Jones Industrial Average (DJIA), l'S&P 500 e il NASDAQ vengono utilizzati per misurare le variazioni del valore delle azioni statunitensi. Molti indici misurano la redditività dei mercati azionari internazionali. Questi indici includono il Nikkei in Giappone, il Dax 30 in Germania e l'SSE Composite in Cina.
Insidie associate all'analisi dei tempi NS x righe
L'importanza di una metodologia che utilizza le informazioni sul passato e sul presente per prevedere il futuro è stata eloquentemente descritta dallo statista Patrick Henry più di duecento anni fa: “Ho solo una lampada che illumina il percorso: la mia esperienza. Solo la conoscenza del passato ci permette di giudicare il futuro".
L'analisi delle serie temporali si basa sul presupposto che i fattori che hanno influenzato l'attività aziendale nel passato e che influenzano il presente continueranno a funzionare in futuro. Se è vero, l'analisi delle serie temporali è uno strumento predittivo e di gestione efficace. Tuttavia, i critici dei metodi classici basati sull'analisi delle serie temporali sostengono che questi metodi sono troppo ingenui e primitivi. In altre parole, un modello matematico che tenga conto dei fattori che hanno operato nel passato non dovrebbe estrapolare meccanicamente le tendenze nel futuro senza tenere conto delle valutazioni degli esperti, dell'esperienza aziendale, dei cambiamenti tecnologici, nonché delle abitudini e delle esigenze delle persone. Nel tentativo di porre rimedio a questa situazione, negli ultimi anni, gli econometrici hanno sviluppato sofisticati modelli informatici dell'attività economica che tengono conto dei fattori sopra elencati.
Tuttavia, i metodi di analisi delle serie temporali sono un eccellente strumento di previsione (sia a breve che a lungo termine) se applicati correttamente, in combinazione con altri metodi di previsione e tenendo conto del giudizio e dell'esperienza degli esperti.
Riepilogo. In questa nota, utilizzando l'analisi delle serie temporali, sono stati sviluppati modelli per prevedere il reddito di tre società: Wm. Wrigley Jr. Company, Cabot Corporation e Wal-Mart. Vengono descritti i componenti delle serie temporali, nonché diversi approcci alla previsione delle serie temporali annuali: il metodo della media mobile, il metodo di livellamento esponenziale, i modelli lineari, quadratici ed esponenziali, nonché un modello autoregressivo. Viene considerato un modello di regressione contenente variabili fittizie corrispondenti alla componente stagionale. Viene mostrata l'applicazione del metodo dei minimi quadrati per la previsione di serie temporali mensili e trimestrali (Fig. 29).
I gradi di libertà P vengono persi quando si confrontano i valori delle serie temporali.
Tecniche di previsione delle serie temporali
1. La previsione come compito dell'analisi delle serie temporali. Componenti deterministiche e casuali: modalità per individuarle e valutarle.
La previsione è l'identificazione scientifica di percorsi probabilistici e risultati del prossimo sviluppo di fenomeni e processi, valutazione di indicatori di processo per un futuro più o meno lontano.
Il cambiamento di stato del fenomeno osservato (processo) è caratterizzato da un insieme di parametri x1, x2,…, xt,…, misurati in tempi successivi. Questa sequenza è chiamata serie temporale.
L'analisi delle serie temporali è uno dei rami della scienza della previsione.
Se si considerano contemporaneamente più caratteristiche del processo, in questo caso si parla di serie temporali multidimensionali.
La componente deterministica (regolare) della serie storica x1, x2,…, xn è intesa come una sequenza numerica d1, d2,…, dn, i cui elementi sono calcolati secondo una certa regola in funzione del tempo t.
Se escludiamo la componente deterministica dalla serie, il resto sembrerà caotico. Si chiama componente casuale ε1, ε2,…, εn.
Modelli di scomposizione delle serie temporali in componenti deterministiche e casuali:
1. Modello additivo:
xt = dt + εt, t = 1,… n
2. Modello moltiplicativo:
xt = dt · εt, t = 1,… n
Se il modello moltiplicativo è logaritmico, otteniamo un modello additivo per i logaritmi di xt.
La componente deterministica comprende:
1) Trend (trt) è una componente non ciclica che cambia gradualmente e descrive l'influenza netta di fattori a lungo termine, il cui effetto si fa sentire gradualmente.
2) Componente stagionale (St) - riflette la ricorrenza dei processi nel tempo.
3) Componente ciclica (Ct) - descrive lunghi periodi di relativi alti e bassi.
4) L'intervento è un impatto significativo a breve termine su una serie storica.
Modelli di tendenza:
- lineare: trt = b0 + b1t
- modelli non lineari:
polinomio: trt = b0 + b1t + b2t2 +… + bntn
logaritmico: trt = b0 + b1 ln (t)
logistica:
esponenziale: trt = b0 b1t
parabolico: trt = b0 + b1t + b2t2
iperbolico: trt = b0 + b1 / t
La tendenza viene utilizzata per le previsioni a lungo termine.
Evidenziare una tendenza:
1) Metodo dei minimi quadrati (il tempo è un fattore, le serie temporali una variabile dipendente):
xti = f (ti, θ) + εt i = 1,… n
f - funzione di tendenza;
θ - parametri sconosciuti del modello delle serie temporali.
εt - variabili casuali indipendenti ed equamente distribuite.
Se la funzione è ridotta a icona, è possibile trovare i parametri .
2) Applicazione degli operatori differenza
![]()
Evidenzia gli effetti stagionali
Sia m - il numero di periodi, p - il valore del periodo.
St = St + p, per ogni t.
1) Valutazione della componente stagionale
a) Effetti stagionali sullo sfondo del trend
Per il modello additivo xt = trt + St + εt la stima è:
Se è necessario che la somma degli effetti stagionali sia uguale a 0, passare alle stime corrette degli effetti stagionali:

Per il modello moltiplicativo xt = trt * St * εt:

b) Se nella serie è presente una componente ciclica (metodo della media mobile)
L'idea del metodo: ogni valore del VR iniziale viene sostituito con un valore medio su un intervallo di tempo, la cui lunghezza è selezionata in anticipo. L'intervallo selezionato scorre lungo la riga.
Media mobile con livellamento mediano: t = med (xt-m, xt-m + 1, ..., xt + m)
Con il livellamento della media aritmetica:
xt = 1 / (2m + 1) (xt-m + xt-m + 1 + ... + xt + m), se p è pari,
xt = 1 / (2m) (1/2 * xt-m + xt-m + 1 +… + 1/2 * xt + m) se p è dispari.
Per il modello additivo, xt = trt + Ct + St + εt.
Per semplificare la notazione: inizia la numerazione dei valori da uno, cambia la numerazione della serie originale in modo che il termine xt corrisponda al valore di x.
- una media mobile con periodo p, tracciata sulla base di xt.
Per un modello moltiplicativo, vai ai logaritmi e ottieni un modello moltiplicativo.
xt = trt Ct St εt
yt = log xt, dt = log trt, gt = log Ct, rt = log St, δt = log εt
yt = dt + gt + rt + δt
2) Rimozione della componente stagionale (allineamento stagionale)
a) Se esistono stime della componente stagionale:
Per il modello additivo, sottraendo dai valori iniziali un numero di stime stagionali ottenute.
Per un modello moltiplicativo, dividendo i valori iniziali della serie per le corrispondenti stime stagionali e moltiplicando per 100%.
b) Applicazione degli operatori differenza
dove B è l'operatore di spostamento all'indietro.
Operatore differenza del secondo ordine:
Se BP contiene una tendenza e una componente stagionale allo stesso tempo, la loro rimozione è possibile con l'aiuto dell'applicazione sequenziale di operatori di differenza semplici e stagionali. L'ordine della loro applicazione non è essenziale:
3) Previsione utilizzando la componente stagionale:
Per il modello additivo:
![]()
Per un modello moltiplicativo:

2. Modelli di serie temporali: AR (p), MA (q), ARIMA (p, d, q). Identificazione del modello, stima dei parametri, ricerca dell'adeguatezza del modello, previsione.
Per descrivere la componente probabilistica di una serie temporale si utilizza il concetto di processo casuale.
Un processo casuale x (t) definito su un insieme T è una funzione di t, i cui valori per ogni t T sono una variabile casuale.
I processi casuali le cui proprietà probabilistiche non cambiano nel tempo sono detti stazionari (aspettativa e varianza sono costanti).
Come modello di serie temporali stazionarie, vengono spesso utilizzati i seguenti:
media mobile;
Le loro combinazioni.
Per verificare la stazionarietà di un numero di residui e stimarne la varianza, utilizzare:
Funzione di autocorrelazione selettiva (correlogramma);
Funzione di autocorrelazione privata.
Sia ε un processo di rumore bianco, ad es. a tempi t diversi, le variabili casuali εt sono indipendenti ed equamente distribuite con i parametri M (εt) = 0, D (εt) = σ2 = const. Quindi:
Un processo casuale x (t) con media μ è detto processo di autoregressione di ordine p (AR (p)) se vale la seguente relazione:
x (t) -μ = α1 (x (t-1) - μ) + α2 (x (t-2) - μ) +… + αp (x (t-p) - μ) + εt
Un processo casuale x (t) è detto processo a media mobile di ordine q (MA (q)) se soddisfa la seguente relazione:
x (t) = εt + β1 εt-1 +… + βq εt-q
Un processo casuale x (t) è detto processo a media mobile autoregressiva di ordini p e q (ARMA (p, q)) se vale la seguente relazione:
I processi tecnici ed economici non stazionari possono essere descritti da un modello ARMA modificato (p, q). Gli operatori di differenza possono essere utilizzati per rimuovere una tendenza.
Siano date due successioni U = (…, U-1, U0, U1,…) e V = (…, V-1, V0, V1, V2,…) tali che:
significa per
![]() significa ecc.
significa ecc.
Quindi il processo AR (p) è rappresentato nella forma,
MA (q): ![]() ,
,
ARMA (p, q): ![]()
B può essere usato come operatore differenza, ad es. ![]()
equivalente a V = (1-B) U
Per differenze di secondo ordine:
z = (1-B) V = (1-B) 2U

dove è l'operatore differenza di ordine d; x = (1-B) dx.
Identificare il modello - determinarne i parametri p, d e q. I grafici delle funzioni di autocorrelazione privata (ACF) e delle funzioni di autocorrelazione privata (PACF) vengono utilizzati per identificare il modello.
ACF. Il k-esimo membro dell'ACF è determinato dalla formula:
 (*)
(*)
Il parametro k è chiamato lag. In pratica k< n/4. График АКФ – коррелограмма. Если полученный ряд остатков нестационарный, то по коррелограмма можно определить причины нестационарности.
I valori del PACF akk si trovano risolvendo il sistema Yule - Walker utilizzando i valori dell'ACF
Yule - Sistema Walker:
R1 = a1 + a2 * r1 +… + ap * rp-1
r2 = a1 * r1 + a2 +… + ap * rp-2
………………………………..
rp = a1 * rp-1 + a2 * rp-2 +… + ap
Dopo aver visualizzato la serie e rimosso il trend, viene considerato l'ACF. Se il grafico ACF non ha una tendenza all'attenuazione, allora questo è un processo non stazionario (modello ARIMA). In presenza di fluttuazioni stagionali, il correlogramma contiene scoppi periodici, di regola, corrispondenti al periodo di fluttuazioni. Si considerano differenze del 1°, 2°, ...k° ordine, finché la serie non diventa stazionaria, quindi il parametro d = k (di solito k non è maggiore di 2). Passiamo all'identificazione del modello stazionario.
Identificazione dei modelli stazionari:
L'ACF diminuisce gradualmente;
CHAKF termina al ritardo p.
L'ACF termina al lag q.
CHAKF cade senza intoppi.
Stima dei parametri m, ai del modello AR(p):
Come stima di m, possiamo prendere il valore medio della BP

Per stimare ai, troviamo la correlazione tra X (t) e X (t-k):
La soluzione generale di questa equazione rispetto a rk è determinata dalle radici dell'equazione caratteristica
Lascia che le radici dell'equazione caratteristica siano diverse. Allora la soluzione generale può essere scritta come:
Dal requisito di stazionarietà segue che tutti | λi |<1.
Se scriviamo l'equazione (**) per k = 1, 2, 3 ...., otteniamo il sistema Yule-Worker per il processo AR (p):
r1 = a1 + a2 * r1 +… + ap * rp-1
r2 = a1 * r1 + a2 +… + ap * rp-2
………………………………..
rp = a1 * rp-1 + a2 * rp-2 +… + ap
Risolvendo questo sistema rispetto a a1, a2 .... ap, si ottengono i parametri AR (p).
Stima del parametro βi del modello MA (q):
Per il processo MA (q) con | k | > qCov = 0.
Cov = s2 * (bk + b1 * bk + 1 + b2 * bk + 2 +… + bq-k * bq)
La funzione di autocorrelazione ha quindi la forma:
 (***)
(***)
Esistono diversi modi per stimare i coefficienti bi lungo il segmento di traiettoria osservato. Il più semplice:
Trova i coefficienti di correlazione ![]() secondo la formula (*). Dal sistema (***) si ottiene un sistema di equazioni non lineari per trovare bi. Si risolve con metodi iterativi.
secondo la formula (*). Dal sistema (***) si ottiene un sistema di equazioni non lineari per trovare bi. Si risolve con metodi iterativi.
Previsione. Durante la previsione, è necessario ottenere i valori deterministici di BP secondo le formule esistenti, quindi calcolare i valori casuali secondo il modello adattato e correggere i valori deterministici per il valore dei valori casuali.
3. Previsione mediante reti neurali artificiali, il metodo delle finestre.
La soluzione di problemi matematici utilizzando le reti neurali (NN) viene effettuata insegnando metodi NN per risolvere questi problemi.
Una rete neurale multistrato viene addestrata utilizzando il metodo Back Propagation.
Modello di neurone artificiale

dove xi sono segnali di ingresso,
ai - coefficienti di conduttività (const), che vengono corretti nel processo di apprendimento,
F è una funzione di attivazione, è non lineare, può essere chiamata in modo diverso in diversi modelli. Ad esempio, "sigmoide":
Struttura generale della rete neurale:
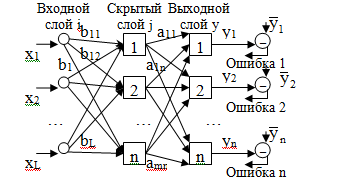
Possono esserci diversi livelli nascosti, quindi la rete neurale è multilivello.
- vettore dei segnali di riferimento (desiderato)
yi - vettore di segnali reali (in uscita)
xi - vettore dei segnali di ingresso.
Strategia di apprendimento supervisionato
Passaggi tipici:
1) Selezionare la coppia di allenamento successiva dal set di allenamento.
x - vettore di input;
- il corrispondente desiderato (vettore di uscita).
Invia il vettore di input x all'input del NS.
2) Calcolare l'uscita di rete y - il segnale di uscita reale.
In precedenza, i coefficienti di peso aij e bij sono impostati arbitrariamente in modo casuale.
3) Calcolare la deviazione (errore): ![]()
4) Correggere i pesi aij e bij della rete in modo da minimizzare l'errore.
![]()
5) Ripetere i passaggi 1-4.
Il processo viene ripetuto finché l'errore sull'intero training set non scende al valore richiesto.
Passaggio del segnale X in avanti sulla rete:
Una coppia viene presa dal training set. Per ogni strato, partendo dal primo, si calcola Y: Y = F (X A),
dove A è la matrice dei pesi degli strati;
F - funzione di attivazione.
Calcoli - strato per strato.
Passaggio inverso dell'errore su NN:
I pesi dei livelli di output sono in fase di regolazione. Per questo, viene applicata una regola delta modificata.
Riso. Allenare un peso dal neurone p nello strato nascosto j al neurone q nello strato di output k
Per il neurone di uscita, viene prima trovato il segnale di errore
![]()
εq viene moltiplicato per la derivata della funzione di contrazione calcolata per questo neurone nello strato k. Otteniamo il valore δ:
Δapqk = α δqk ypj,
dove α è il coefficiente del tasso di apprendimento (0,01≤ α<1) – const, подбирается экспериментально в процесса обучения.
ypj - segnale di uscita del neurone p dello strato j.
 - il valore del peso in un fascio di neuroni p → q al passo t (prima della correzione) e al passo t + 1 (dopo la correzione).
- il valore del peso in un fascio di neuroni p → q al passo t (prima della correzione) e al passo t + 1 (dopo la correzione).
Regola i pesi del livello nascosto.
Consideriamo un neurone dello strato nascosto p. Andando avanti, questo neurone trasmette il suo segnale di uscita ai neuroni dello strato di uscita attraverso i pesi che li collegano. Durante l'allenamento, questi pesi funzionano in ordine inverso, passando il valore di dall'output al livello nascosto.
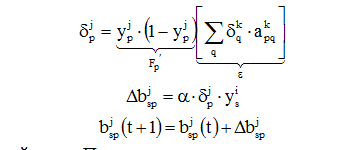
E così per ogni coppia. Il processo termina se per ogni X NS genererà
Previsione tramite reti neurali. Metodo della finestra.
La serie temporale xt, t = 1,2… T è data. Il problema della previsione si riduce al problema del riconoscimento di pattern sulla rete neurale.
Un metodo per identificare modelli in una serie temporale basato su reti neurali è chiamato "windowing".
Due finestre Wi (input) e Wo (output) di dimensione fissa n e m, rispettivamente, vengono utilizzate per il set di dati osservato.

Queste finestre sono in grado di muoversi con qualche passo S lungo una curva (riga) lungo l'asse del tempo. Il risultato è una sequenza di osservazioni:

La prima finestra Wi, scansiona i dati, li trasferisce all'input del NS e Wo - all'output. La coppia risultante Wji → Wj0, j = 1..n ad ogni passo forma una coppia di addestramento (osservazione). Dopo l'addestramento, la rete neurale può essere utilizzata per le previsioni.
07.10.2013 Tyler Chessman
La comprensione delle idee chiave della previsione delle serie temporali e la familiarità con alcuni dettagli ti offriranno un vantaggio nell'utilizzo delle funzionalità di previsione di SQL Server Analysis Services (SSAS)
Questo articolo descriverà i concetti di base necessari per padroneggiare le tecnologie di data mining. Tratteremo anche alcune delle sottigliezze in modo da non scoraggiarti di fronte a loro nella pratica (vedi la barra laterale "Perché il data mining è così impopolare").
Di tanto in tanto, i professionisti di SQL Server devono fare proiezioni di valore futuro, come entrate o proiezioni di vendita. Le organizzazioni a volte utilizzano la tecnologia di data mining nella creazione di modelli predittivi per fornire tali stime. Una volta compresi i concetti di base e alcuni dettagli, è possibile iniziare a utilizzare correttamente le funzionalità predittive di SQL Server Analysis Services (SSAS).
Metodi di previsione
Esistono vari approcci alla previsione. Ad esempio, il sito Web Forecasting Methods (forecastingmethods.org) distingue tra diverse categorie di metodi di previsione, inclusi casuali (altrimenti chiamati economici e matematici), modelli esperti (soggettivi), serie temporali, intelligenza artificiale, previsioni di mercato, previsioni probabilistiche, modelli di previsione e previsione del metodo basata su classi di riferimento. Il sito web di Forecasting Principles (www.forecastingprinciples.com) fornisce una visualizzazione ad albero dei metodi, separando principalmente i metodi soggettivi (ossia i metodi utilizzati quando non sono disponibili dati sufficienti per l'analisi quantitativa) e statici (ossia i metodi utilizzati quando sono disponibili i dati numerici corrispondenti) . In questo articolo, mi concentrerò sulla previsione delle serie temporali, un tipo di approccio statico in cui ci sono abbastanza dati accumulati per prevedere le metriche.
La previsione delle serie temporali presuppone che i dati del passato aiutino a spiegare i valori futuri. È importante capire che in alcuni casi si tratta di dettagli che non si riflettono nei dati accumulati. Ad esempio, emergerà un nuovo concorrente che potrebbe influire negativamente sui guadagni futuri o rapidi cambiamenti nella forza lavoro che potrebbero influire sui tassi di disoccupazione. In situazioni come questa, la previsione delle serie temporali potrebbe non essere l'unico approccio. Spesso, diversi approcci di previsione vengono combinati per fornire le previsioni più accurate.
Comprendere le basi della previsione delle serie temporali
Una serie storica è una raccolta di valori ottenuti in un periodo di tempo, solitamente a intervalli regolari. Esempi comuni includono vendite settimanali, spese trimestrali e tassi di disoccupazione mensili. I dati delle serie temporali sono presentati in un formato grafico, con intervalli di tempo lungo l'asse x del grafico e valori lungo l'asse y, come mostra la Figura 1.
Quando si considera come un valore cambia da un periodo all'altro e come prevedere i valori, è necessario tenere presente che i dati delle serie temporali hanno alcune caratteristiche importanti.
- Livello base. La linea di base è generalmente definita come la media di una serie temporale. In alcuni modelli di previsione, la linea di base è generalmente definita come il valore iniziale dei dati della serie.
- Tendenza La tendenza di solito mostra come le serie temporali cambiano da un periodo all'altro. Nell'esempio mostrato in Figura 1, il numero di disoccupati ha una tendenza all'aumento dall'inizio del 2008 a gennaio 2010, dopodiché la linea di tendenza scende. Per informazioni sull'insieme di dati di esempio utilizzati per tracciare i grafici in questo articolo, vedere la barra laterale "Calcolo del tasso di disoccupazione".
- Fluttuazioni stagionali. Alcuni valori tendono ad aumentare o diminuire a seconda di determinati periodi di tempo, questo può essere un giorno della settimana o un mese dell'anno. Considera l'esempio delle vendite al dettaglio, che spesso raggiungono il picco durante il periodo natalizio. Nel caso della disoccupazione, osserviamo un andamento stagionale, massimo a gennaio e luglio e minimo a maggio e ottobre, come mostra la figura 2.
- Rumore. Alcuni modelli di previsione includono una quarta caratteristica, rumore o errore, che si riferisce a fluttuazioni casuali e movimenti a scatti nei dati. Non prenderemo in considerazione il rumore qui.
Pertanto, identificando la tendenza, sovrapponendo la linea di tendenza alla linea di base e identificando il componente stagionale che può verificarsi durante l'analisi dei dati, si dispone di un modello di previsione che è possibile utilizzare per prevedere i valori:
Valore previsto = Baseline + Trend + Componente stagionale
Definire la linea di base e la tendenza
L'unico modo per determinare la linea di base e la tendenza è utilizzare il metodo di regressione. La parola "regressione" qui si riferisce alla considerazione della relazione tra le variabili. In questo caso esiste una relazione tra la variabile indipendente del tempo e la variabile dipendente del numero di disoccupati. Si noti che la variabile esplicativa è talvolta chiamata predittore.
Utilizzare uno strumento come Microsoft Excel per applicare il metodo di regressione. Ad esempio, è possibile eseguire un conteggio automatico in Excel e aggiungere una linea di tendenza a un grafico di serie temporali utilizzando il menu Trendline nella scheda Layout strumenti grafico o la scheda Layout strumenti grafico pivot nel riquadro Excel 2010 o Excel 2007. Nella Figura 1, I aggiunta una linea di tendenza dritta selezionando la modalità Linea di tendenza lineare nel menu Trendline. Quindi ho selezionato Altre opzioni della linea di tendenza dal menu Linea di tendenza, quindi le opzioni Visualizza equazione sul grafico e Visualizza valore R-quadrato sul grafico, vedi Figura 3.
.jpg) |
| Figura 3: Opzioni di tendenza in Excel |
Questo processo di adattamento di una linea di tendenza ai dati accumulati è chiamato regressione lineare. Come possiamo vedere nella Figura 1, la trendline viene calcolata secondo l'equazione, dove vengono determinati il livello base (8248,8) e il trend (104,67x):
y = 104,67x + 8248,8
Puoi pensare a una linea di tendenza come una serie di coordinate dell'asse x-y in cui puoi includere un intervallo di tempo (ovvero l'asse x) per ottenere un valore (asse y). Excel determina la linea di tendenza "migliore" utilizzando il metodo dei minimi quadrati (definito come R² nella Figura 1). Una linea dei minimi quadrati è una linea che riduce al minimo la distanza verticale al quadrato da ciascun punto sulla linea di tendenza al punto corrispondente sulla linea. I valori RMS consentono di determinare che le deviazioni sopra o sotto la linea effettiva non si annullano a vicenda. Nella Figura 1 vediamo che R² = 0,5039, il che significa che la relazione lineare spiega il 50,39% della variazione delle statistiche sulla disoccupazione nel tempo.
Trovare una linea di tendenza accurata in Excel spesso comporta tentativi ed errori, insieme all'ispezione visiva. Nella Figura 1, una linea di tendenza dritta non si adatta bene. Excel offre altre opzioni della linea di tendenza che vedi nella Figura 3. Nella Figura 4, ho aggiunto una linea di media mobile a quattro periodi che viene tracciata in base alla media aritmetica dei periodi corrente e dell'ultimo set nella serie temporale.
Inoltre, ho aggiunto una linea di tendenza polinomiale applicando un'equazione algebrica per tracciare la linea. Si noti che la linea di tendenza del polinomio ha un valore R² di 0,9318, che indica la migliore relazione in termini di relazione tra le variabili indipendenti e dipendenti. Tuttavia, un valore R² più elevato non significa necessariamente che la linea di tendenza fornirà una qualità predittiva. Esistono altri metodi per fare previsioni accurate, che descriverò brevemente di seguito. Alcune opzioni per una linea di tendenza in Excel (ad esempio una linea di tendenza lineare e polinomiale) consentono di effettuare previsioni sia in avanti che in direzione opposta, tenendo conto del numero di periodi, con il tracciamento dei valori ottenuti sul grafico. Ad alcuni, l'espressione "previsione nella direzione opposta" può sembrare strana. Questo è meglio illustrato con un esempio. Supponiamo che un nuovo fattore - un rapido aumento dei posti di lavoro nel settore pubblico (ad esempio, lavori per la difesa nazionale nei primi anni 2000, dipendenti temporanei dell'Ufficio censimento degli Stati Uniti) - abbia prodotto un rapido calo della disoccupazione. È necessario prevedere il tasso di crescita del settore dei nuovi posti di lavoro nella direzione opposta per diversi mesi, quindi ricalcolare il tasso di disoccupazione per arrivare a una misura appiattita del cambiamento.
Puoi anche applicare manualmente l'equazione della linea di tendenza per calcolare i valori in prospettiva. Nella Figura 5, ho aggiunto una linea di tendenza polinomiale di previsione a 6 mesi rimuovendo prima i dati degli ultimi 6 mesi (ovvero da aprile a settembre 2012) dalla serie temporale originale.
Se confronti la Schermata 5 con la Schermata 1, noterai che le previsioni polinomiali hanno una tendenza al rialzo, che non corrisponde alla tendenza al ribasso (tendenza) della serie temporale effettiva.
Ci sono due punti importanti da fare sulla regressione.
- Come accennato in precedenza, la regressione lineare include una variabile indipendente e una dipendente. Per capire come variabili esplicative aggiuntive potrebbero spiegare i cambiamenti nella variabile dipendente, prova a costruire un modello di regressione multipla. Nel contesto della previsione del numero di disoccupati negli Stati Uniti, è possibile aumentare R² (e l'accuratezza della previsione) considerando il tasso di crescita dell'economia, la popolazione degli Stati Uniti e la crescita del numero di lavoratori occupati . SSAS può inserire molte variabili (ad es. regressori) in un modello di previsione delle serie temporali.
- Gli algoritmi di previsione delle serie temporali, inclusi quelli utilizzati in SSAS, calcolano l'autocorrelazione, ovvero la correlazione tra valori di serie temporali adiacenti. Un modello di previsione che coinvolge direttamente l'autocorrelazione è chiamato modello autoregressivo (AR). Ad esempio, un modello di regressione lineare costruisce un'equazione di tendenza basata su un periodo (ad esempio, 104,67 * x), mentre un modello AR costruisce un'equazione basata su valori precedenti (ad esempio, -0,417 * disoccupato (-1) + 0,549 * impiegato (-1)). Il modello AR aumenta potenzialmente l'accuratezza della previsione poiché tiene conto di informazioni aggiuntive al di sopra della tendenza e della componente stagionale.
Teniamo conto della componente stagionale
La componente stagionale nella struttura di una serie storica si manifesta solitamente in connessione con il giorno della settimana, o con il giorno del mese, o con il mese dell'anno. Come notato sopra, il numero di disoccupati negli Stati Uniti di solito aumenta e diminuisce in un dato anno solare. Questo è vero anche se l'economia cresce, come mostra la Figura 2. In altre parole, per fare una previsione accurata, è necessario tenere conto della componente stagionale. Un approccio generale consiste nell'applicare il livellamento della stagionalità. In Practical Time Series Forecasting: A Hands-On Guide, Second Edition (CreateSpace Independent Publishing Platform, 2012), l'autore Galit Shmueli consiglia di utilizzare uno dei tre metodi seguenti:
- calcolo di una media mobile;
- analisi delle serie temporali a un livello meno dettagliato (ad esempio, considerare le variazioni del numero di disoccupati per trimestre anziché per mese);
- analisi delle singole serie storiche (e calcolo delle previsioni) per stagione.
La linea di base e la tendenza vengono determinate durante il calcolo della previsione in base a una serie temporale livellata. Facoltativamente, il componente stagionale o l'aggiustamento possono essere riapplicati ai valori di previsione basati sui valori del fattore stagionale iniziale quando si utilizza il metodo Holt-Winters. Se vuoi vedere come viene calcolata la stagionalità in Excel, cerca nel web "metodo Winters in Excel". Inoltre, per un'ampia spiegazione del metodo Holt-Winters, vedere Microsoft Office Excel 2007 di Wayne L. Winston: analisi dei dati e modellazione aziendale, seconda edizione (Microsoft Press, 2007).
In molti pacchetti di data mining, come SSAS, gli algoritmi di previsione delle serie temporali tengono automaticamente conto delle variazioni stagionali misurando le relazioni stagionali e incorporandole in un modello di previsione. Tuttavia, potresti voler impostare suggerimenti sul modello dei cambiamenti stagionali.
Precisione di misurazione del modello di previsione
Come discusso in precedenza, il modello originale (utilizzando il metodo dei minimi quadrati) non fornisce necessariamente l'accuratezza delle previsioni. Il modo migliore per testare l'accuratezza delle stime predittive consiste nel dividere le serie temporali in due set di dati, uno per la costruzione (ovvero l'addestramento) del modello e l'altro per la convalida. Il set di dati di convalida sarà la parte più recente nel set di dati originale e idealmente coprirà un tempo pari alla cronologia delle previsioni per il futuro. Per verificare (convalidare) il modello, i valori previsti vengono confrontati con i valori effettivi. Si noti che dopo aver convalidato il modello, il modello può essere ricostruito utilizzando l'intera serie temporale, quindi è consigliabile utilizzare gli ultimi valori effettivi per prevedere i valori futuri delle metriche.
Quando si misura l'accuratezza di un modello predittivo, in genere sorgono due domande: come determinare l'accuratezza della stima predittiva e quanti dati storici utilizzare per addestrare il modello.
Come determinare l'accuratezza di una stima predittiva? In alcuni scenari, i valori previsti al di sopra dei valori effettivi potrebbero non essere desiderabili (ad esempio, nelle proiezioni di investimento). In altre situazioni, i valori previsti al di sotto dei valori effettivi possono avere conseguenze devastanti (ad esempio, prevedere il prezzo di offerta vincente più basso per un oggetto all'asta). Ma nei casi in cui si desidera calcolare un punteggio per tutte le previsioni (non importa se i valori previsti sono superiori o inferiori ai valori reali), è possibile iniziare con un errore quantitativo in una previsione separata utilizzando la definizione:
errore = valore previsto - valore effettivo
Con questa definizione di errore, ci sono due metodi popolari per misurare la precisione: l'errore medio assoluto (MAE) e l'errore percentuale medio assoluto (MAPE). Nel metodo MAE i valori assoluti degli errori di previsione vengono sommati e poi divisi per il numero totale di previsioni. Il metodo MAPE calcola la deviazione assoluta media dalla previsione in percentuale. Per esempi di utilizzo di questi e altri metodi per misurare la qualità delle stime predittive, un modello di Excel (con dati predittivi di esempio e rapporti di precisione), vedere la pagina Web del modello di diagnostica delle metriche della domanda (demandplanning.net/DemandMetricsExcelTemp.htm).
Quanti dati storici dovrebbero essere usati per addestrare il modello? Quando lavori con una serie temporale che ha una lunga storia, potresti voler includere tutti i dati storici nel tuo modello. Tuttavia, a volte la cronologia aggiuntiva non migliora l'accuratezza della previsione. I dati storici possono persino distorcere la previsione se le condizioni del passato differiscono in modo significativo dalle condizioni del presente (ad esempio, la composizione della forza lavoro è diversa ora e in passato). Non ho trovato alcuna formula particolare o metodo pratico che mi dica quanti dati storici includere, quindi suggerisco di iniziare con serie temporali diverse volte più grandi degli intervalli di tempo previsti e quindi di verificarne l'accuratezza. Quindi, prova ad arrotondare il numero della cronologia per eccesso o per difetto e riesegui il test.
Previsione delle serie temporali in SSAS
La previsione delle serie temporali è apparsa per la prima volta in SSAS nel 2005. Per calcolare i valori previsti, l'algoritmo Microsoft Time Series ha utilizzato un singolo algoritmo denominato albero autoregressivo con previsione incrociata (ARTXP) o albero autoregressivo con previsione incrociata. ARTXP combina un metodo autoregressivo con un data mining dell'albero decisionale in modo che l'equazione di previsione possa cambiare (che significa suddivisione) in base a determinati criteri. Ad esempio, un modello di previsione fornirà un adattamento migliore (e una migliore accuratezza della previsione) se si partiziona prima per data e poi in base al valore della variabile esplicativa, come mostra la Figura 6.
.jpg) |
| Figura 6: un esempio di albero decisionale ARTXP in SSAS |
In SSAS 2008, l'algoritmo Microsoft Time Series, oltre a ARTXP, ha iniziato a utilizzare un algoritmo chiamato media mobile integrata autoregressiva (ARIMA), una media mobile integrata con autoregressivo, per calcolare previsioni a lungo termine. ARIMA è considerato lo standard del settore e può essere visto come una combinazione di processi autoregressivi e modelli di media mobile. Inoltre, analizza gli errori di previsione storici per migliorare il modello.
Per impostazione predefinita, l'algoritmo Microsoft Time Series combina i risultati degli algoritmi ARIMA e ARTXP per ottenere previsioni ottimali. Se lo desideri, puoi annullare questa funzione. Diamo un'occhiata alla documentazione della documentazione in linea di SQL Server (BOL):
“L'algoritmo addestra due diversi modelli degli stessi dati: un modello utilizza l'algoritmo ARTXP e l'altro utilizza l'algoritmo ARIMA. L'algoritmo combina quindi i risultati dei due modelli per sviluppare la migliore previsione coprendo un numero variabile di intervalli di tempo. Poiché l'algoritmo ARTXP è più adatto per le previsioni a breve termine, è consigliabile utilizzarlo all'inizio di una serie di previsioni. Tuttavia, se gli intervalli di tempo necessari per la previsione vanno nel futuro, l'algoritmo ARIMA è più significativo. "
Quando si lavora con la previsione delle serie temporali in SSAS, è necessario tenere presente quanto segue:
- Sebbene SSAS disponga di una scheda Grafico di precisione di data mining, non funziona con il data mining per i modelli di serie temporali. Di conseguenza, è necessario misurare manualmente l'accuratezza utilizzando uno dei metodi qui menzionati (ad es. MAE, MAPE) utilizzando uno strumento come Excel per i calcoli.
- SSAS Enterprise Edition consente di suddividere una singola serie temporale in molti "modelli storici" in modo da non dover suddividere manualmente i dati in set di dati per l'addestramento del modello e la verifica dell'accuratezza delle previsioni. Dal punto di vista dell'utente finale, esiste un solo modello di serie temporali, ma è possibile confrontare i risultati effettivi con i risultati previsti all'interno del modello, come mostra la Figura 7.
Passo successivo
In questo articolo, ti ho presentato le basi della previsione delle serie temporali. Abbiamo anche coperto alcuni dettagli degli algoritmi sottostanti in modo che non interferiscano con l'elaborazione delle serie temporali. Come passaggio successivo, ti suggerisco di padroneggiare gli strumenti di previsione delle serie temporali con SSAS. Un esempio è un progetto che utilizza i dati sulla disoccupazione forniti in questo articolo. È quindi possibile visualizzare l'esercitazione TechNet online di Intermediate Data Mining (Analysis Services - Data Mining) all'indirizzo technet.microsoft.com/en-us/library /cc879271.aspx.
Perché il data mining è così impopolare
Le tecnologie di business intelligence (BI) come OLAP sono diventate ampiamente utilizzate nell'ultimo decennio. Allo stesso tempo, Microsoft ha iniziato a promuovere un'altra tecnologia di BI, il data mining, in strumenti popolari come Microsoft SQL Server e Microsoft Excel. Tuttavia, la tecnologia di data mining non ha ancora preso il sopravvento. Come mai? Sebbene la maggior parte delle persone possa comprendere rapidamente i concetti fondamentali del data mining, i dettagli di base degli algoritmi sono indissolubilmente legati a concetti e formule matematici. C'è una grande "discrepanza" tra un alto livello di comprensione astratta e l'esecuzione dettagliata. Di conseguenza, il data mining è visto come una scatola nera dai professionisti IT e dai clienti industriali, il che non favorisce un'adozione diffusa della tecnologia. Questo articolo è il mio tentativo di ridurre la "discrepanza" nella previsione delle serie temporali.
Calcolo del tasso di disoccupazione
Nell'articolo principale, i dati per i grafici si basano sulle informazioni sulla popolazione attiva pubblicate dagli Stati Uniti. Ufficio di statistica del lavoro (http://www.bls.gov/). BLS pubblica i dati sulla disoccupazione basati su un'indagine mensile condotta dall'US Census Bureau (BLS) che estrapola il numero totale di persone occupate e disoccupate. Nello specifico, BLS applica la formula:
Tasso di disoccupazione = disoccupato / (disoccupato + occupato)
È interessante notare che quando si tratta del tasso di disoccupazione, i media di solito citano un coefficiente di stagionalità equalizzato. La regolazione stagionale viene eseguita utilizzando un modello generale chiamato media mobile integrata autoregressiva (ARIMA). Si tratta essenzialmente dello stesso algoritmo utilizzato in molti pacchetti di data mining per la previsione di serie temporali, incluso SQL Server Analysis Services (SSAS). Per ulteriori informazioni sul modello ARIMA utilizzato da BLS, visitare la pagina Web del programma di regolazione stagionale X-12-ARIMA (www.census.gov/srd/www/x12a/). Nota che ho usato valori aggiustati stagionali e non stagionali nel design tipico di questo articolo.
Padroneggiare la previsione delle serie temporali
articoli Correlati